저번 시간까지 우리는 막대 히스토그램 선 등 간단한 그래프만 공부하였습니다.
하지만 저희가 실무에서는 저런 간단한 그래프만 쓸까요?
아니죠 평균 회귀 그래프, 히트맵 그래프 등등 다양한 그래프를 많이 쓰겠죠? 물론 그래프의 종류는 매~~~~~~우 많습니다.
그러니 이번 시간에는 Seaborn이라는 모듈에 대해서 간단히만 알아 볼 것입니다.
더 원하실경우에는 사이트에 직접가서 자신이 원하는 그래프를 어떻게 그려야 되는지 직접 알아보셔야 합니다.
(너무 많아요 정말 ㅠㅠ)
Seaborn
- Seaborn은 데이터 시각화를 위한 Python 라이브러리
- 통계적 그래프를 생성하는데 유용
- Matplotlib 위에 구축되어 있으며, 데이터의 관계, 분포, 카테고리 비교 등을 시각적으로 쉽게 이해할 수 있게 해줌
- Pandas DataFrame과 잘 통합되어 있어 데이터를 간단히 시각화
- Seaborn에는 자체 데이터셋이 포함되어 있어 다양한 테스트를 할 수 있음
Example gallery — seaborn 0.13.2 documentation
seaborn.pydata.org
오늘 우리가 학습할 그래프는
scatterplot , stripplot, swarmplot, relplot, catplot, displot, heatmap, pairplot, regplot
을 공부할 것입니다. 선택한 이유는 대중적이기 때문입니다.
산점도
- sns.scatterplot() : 두 연속형 변수 간의 관계를 시각화
- x, y: x축과 y축에 사용할 데이터 열
- hue : 데이터 포인트의 색상을 그룹으로 구분
- size : 데이터 포인트의 크기를 그룹으로 구분
- style : 데이터 포인트의 스타일(모양)을 그룹으로 구분
- palette : 색상 팔레트 지정
- alpha : 투명도 설정 (0 에서 1 사이 값)
- legend : 범례 표시 여부 ('brief', 'full', False)
- data : 데이터셋(Pandas DataFrame)


데이터는 Seaborn 자체 데이터 셋을 이용 할 수있습니다.
stripplot
- sns.stripplot() : 단순 데이터 분포를 빠르게 보고 싶을 때
- 점들을 한 줄로 나열 : 데이터 포인트를 카테고리별로 한 줄에 나열
- 데이터 포인트들이 겹칠 수 있음
- 단순히 데이터의 분포를 보여주기 때문에 시각적으로 간단함
- jitter : 점들을 수평으로 약간 퍼뜨려서 겹침을 줄임 (기본값 : False)
- hue : 색상을 사용해 그룹 구분
- dodge : 여러 카테고리를 옆으로 나란히 배치 (색상 구분 시 유용)

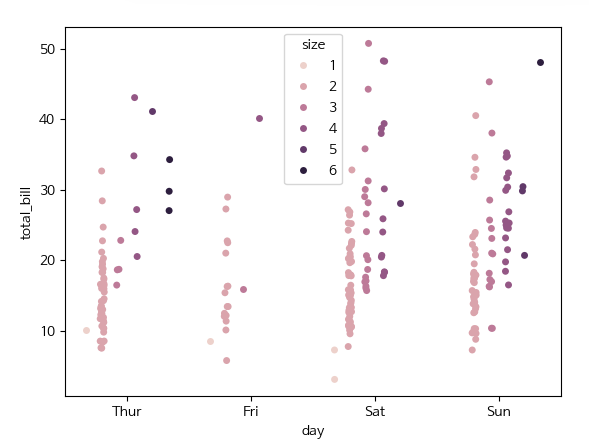
swarmplot
- sns.swarmplot() : 정확한 데이터 분포를 확인하고 싶을 때
- 점들이 겹치지 않도록 정렬 : 데이터를 적절히 분산시켜 서로 겹치지 않게 배치
- 데이터 포인트의 정확한 분포를 더 명확히 보여줌
- stripplot보다 시각적으로 더 읽기 쉬움
- hue : 색상을 사용해 그룹 구분
- dodge : 색상 구분 시 카테고리를 옆으로 나란히 배치

relplot
- sns.relplot() : 관계형 플룻(Relational Plot)을 생성
- x, y : x축과 y축에 사용할 데이터 열
- hue : 색상으로 그룹을 구분
- style : 마커 스타일로 그룹을 구분
- size : 마커 크기로 그룹을 구분
- kind : 플롯 종류 (scatter 또는 line)


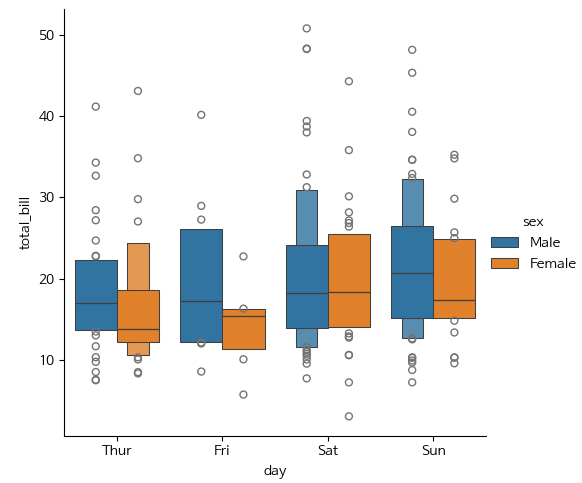
catplot
- sns.catplot() : 카테고리형 데이터의 분포를 시각화
- kind : 플롯 종류 (strip, swarm, box, violin, bar, count)
- hue : 색상으로 그룹을 구분
- col, row : 데이터의 서브셋을 생성하여 서브플롯으로 분할
데이터의 분포를 시각화
- sns.displot() : 데이터의 분포를 시각화
- kind : 분포 그래프 종류 (hist, kde, ecdf)
- bins : 히스토그램의 빈 수
- hue : 색상으로 그룹을 구분

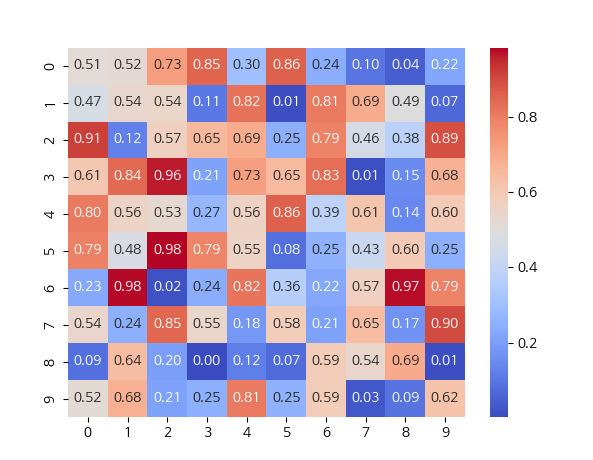
HeatMap 그래프
- sns.heatmap() : 2차원 데이터(매트릭스)를 히트맵 형태로 시각화
- impoty numpy as np 는 예시를 위해서 사용
- annot : 셀에 값을 표시 여부 (True / False)
- fmt : 셀에 표시될 값의 포맷
- cmap : 컬러맵 지정
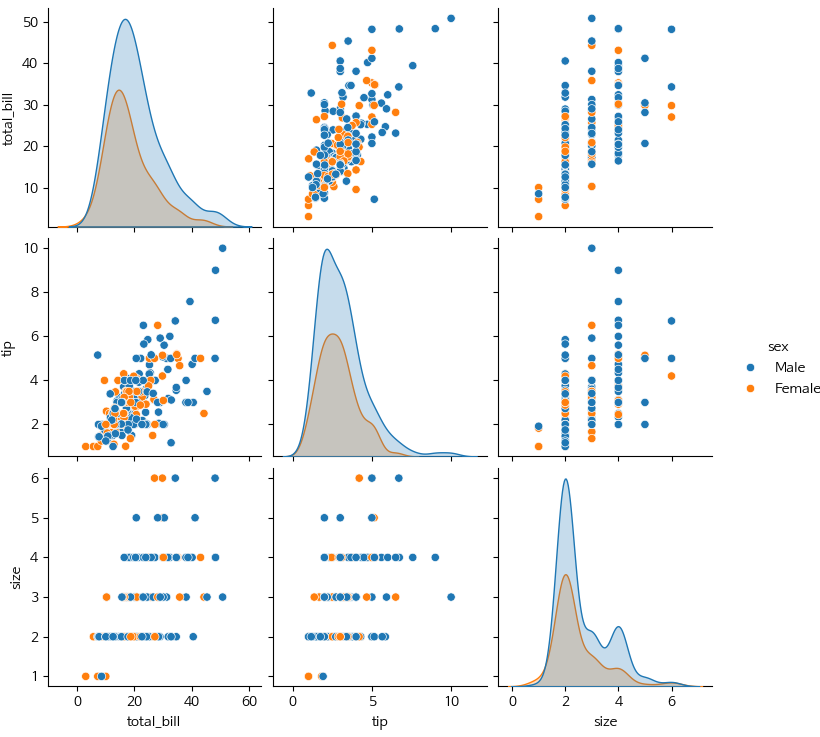
pairplot 그래프
- sns.pairplot() : 여러 변수 간의 관계를 한 번에 시각화
- hue : 색상으로 그룹을 구분
- diag_kind : 대각선에 표시할 그래프 종류 (kde, hist)

회귄선이 포함된 산점도
- sns.regplot () : 회귀선이 포함된 산점도를 생성
- x, y: 축과 y축에 사용할 데이터 열
- hue : 색상으로 그룹을 구분
- order : 다항 회귀의 차수


오늘은 이렇게 여러가지 그래프를 같이 공부하였습니다.
오늘은 간단한 과제 하나를 내드리겠습니다.
하지만, 이과제로 seaborn 다배웠다 하지 마시고 아까 말했듯이 그래프 데이터가 정~~~~~~말 많기 때문에 꼭 사이트에 들어가셔서 신기하거나 표현하고 싶은 그래프를 클릭하여 직접 표현해 보시길 바랍니다.
과제 (데이터 분석 후 그래프 그리기)
- flights 데이터 셋 이용하기
- 조건
- 연도(year)별 승객 수(passengers)의 평균을 꺾은선 그래프로 나타내세요.
- 연도와 월별(month) 승객 수를 히트맵으로 시각화 하세요.
- 특정 연도(예: 1958년)의 월별 승객 수를 막대 그래프로 나타내세요.
해답은 하루코딩에 올려 놓겠습니다.
오늘도 같이 공부하시느라 수고 많으셨습니다!!!!!!
다음시간에는 머신러닝에 사용되는 opencv를 같이 공부할 것입니다.
그러니 머신러닝이 무엇인지 먼저 공부하고 오시면 학습하기 편하실 겁니다.
데이터 가져오기에서 같이 공부하도록 합시다~~~~

'python 시작하기' 카테고리의 다른 글
| python OPEN CV를 더욱 깔끔하게 전 처리 해보자! (1) | 2025.01.08 |
|---|---|
| python OPEN CV를 활용하여 이미지를 저장해보자! (0) | 2025.01.08 |
| Python 데이터 시각화 (2) (1) | 2024.12.17 |
| Python 데이터 시각화 (1) | 2024.12.16 |
| python Pandas (2) | 2024.12.15 |



